|
|

|

|
| e-Pub |
Section: New Results
Pedestrian Detection: Training Set Optimization
Participants : Remi Trichet, Javier Ortiz.
keywords: computer vision, pedestrian detection, classifier training, data selection, data generation, data weighting, feature extraction
|
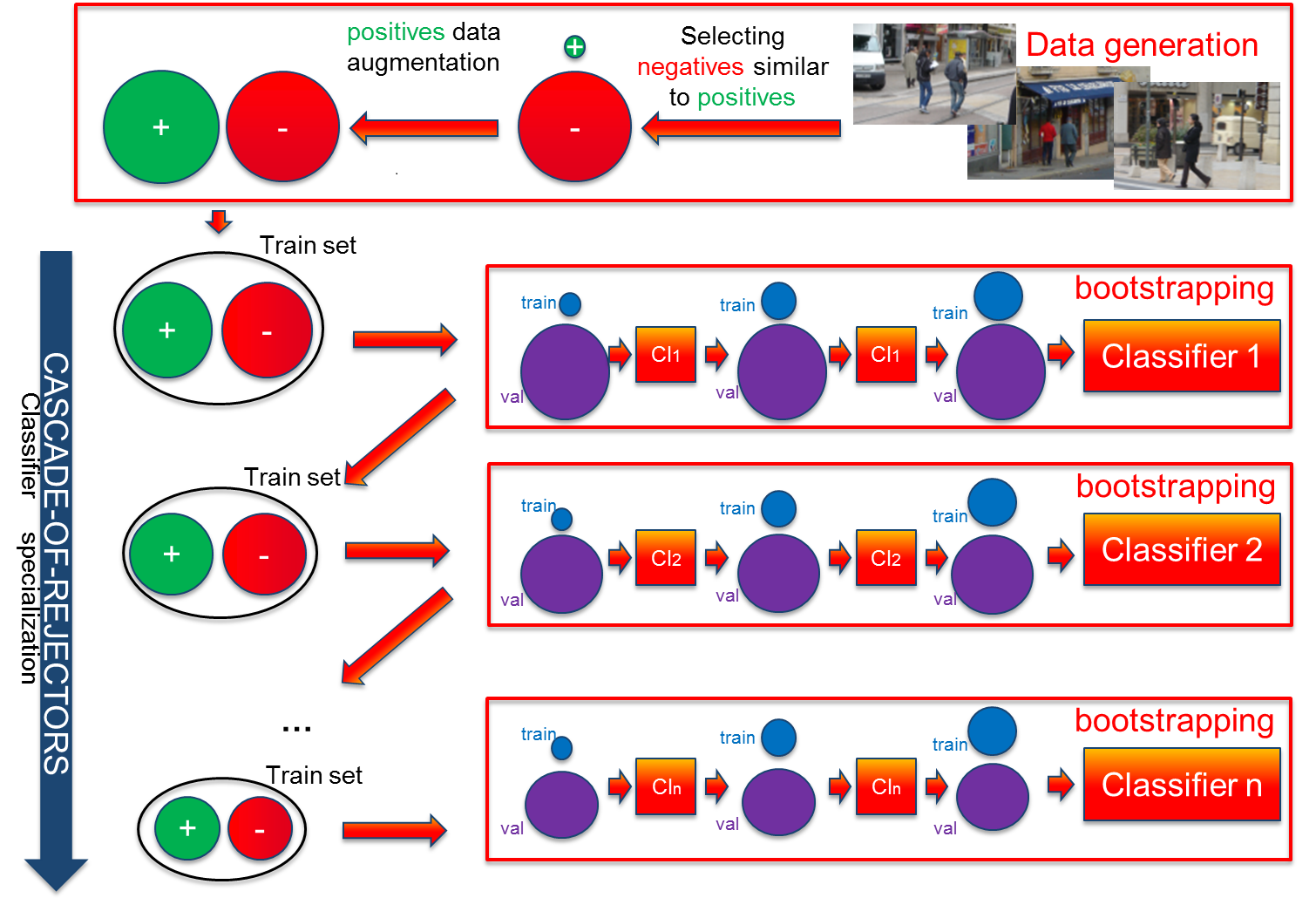
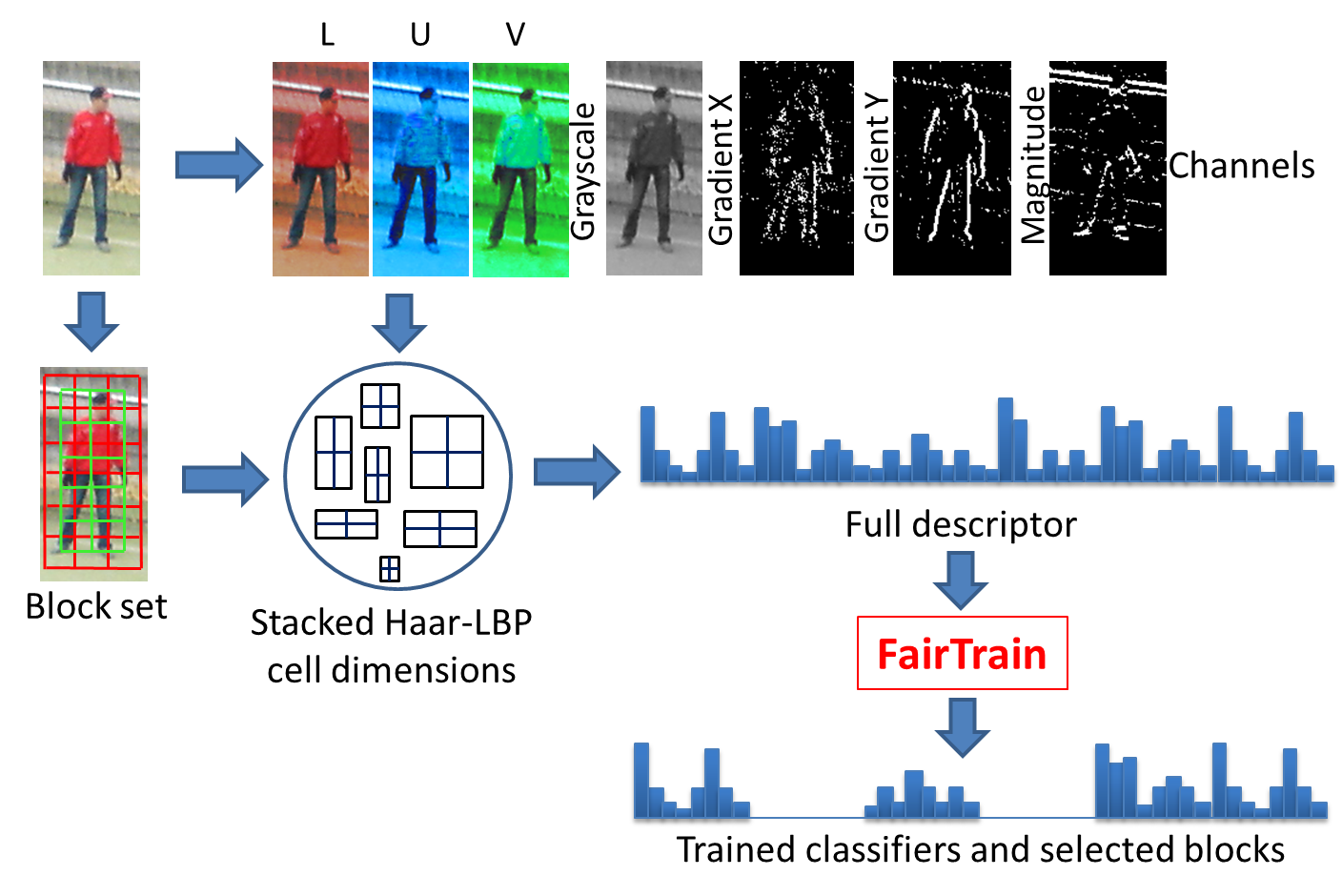
This year's work builds on the near real-time pedestrian detector introduced last year. Let's recall that this detector novelty mainly focusses on our training set generation protocol, named FairTrain [39]. The methodology, illustrated in figure 5, decomposes in two distinct parts: The initial training set generation and the classifier training. The initial training set generation carefully selects data from a set of images while balancing negative and positive sample cardinalities. We then train a cascade of 1 to n classifiers. This cascade could consist of a cascade-of-rejectors [57], [143], [48], [118], [122], a soft cascade [99], or both. In addition, each independent classifier is learnt through bootstrapping [59], [69] to improve performance. One key aspect is to seek balanced positive and negative sets at all time. Hence, all along the cascade, the minority class is oversampled to create balanced positive and negative sets. See [39] for details.
This year's improvement on this framework is two-fold: refined experimentation and Local Binary Pattern (LBP) channel descriptor.
In many aspects, the construction of a training set remains similar to what it was at the birth of the domain, some related problems are not well studied, and sometimes still tackled empirically. This work studies the pedestrian classifier training conditions. More than a survey of existing training techniques, our experimentation highlights impactful parameters, potential new research directions, and combination dilemmas. They allowed us to better understand and parametrized our pipeline. Second, we introduce a 12-valued filter representation based on LBP. Indeed, various improvements now allow for this texture feature to provide a very discriminative, yet compact descriptor. This new LBP-based channel descriptor outperforms channel features [65] while requiring a fraction of the original LBP memory footprint. Uniform patterns [100] and Haar-based LBP [56] are employed to shrink the filter dimension in accordance to our needs. Also, cell stacking and new filter combination restriction based on proposal window coverage are successfully applied. Finally, a more reliable feature selection technique is introduced to construct a lower dimension final descriptor without harming its discriminability. Experiments on the Inria and Caltech-USA datasets, respectively presented in tables 1 and 2 validate these progresses.
In the light of these results, combining the FairTrain data selection pipeline with CNN features appears like the obvious next step.
| Evaluation method | Log-average miss rate | Speed(CPU/GPU) |
| HoG [59] | 46% | 0.5fps |
| HoG-LBP [127] | 39% | Not provided |
| MultiFeatures [129] | 36% | 1fps |
| FeatSynth [45] | 31% | 1fps |
| MultiFeatures+CSS [123] | 25% | No |
| Channel Features [65] | 21% | 0.5fps |
| FPDW [64] | 21% | 2-5fps |
| DPM [70] | 20% | 1fps |
| RF local experts [95] | 15.4% | 3fps |
| PCA-CNN [81] | 14.24% | 0.1fps |
| CrossTalk cascades [66] | 18.98% | 30-60fps |
| VeryFast [46] | 18% | 8/135fps |
| WordChannels [57] | 17% | 0.5/8fps |
| SSD [92] | 15% | 56fps |
| LBP-Channels full | 14.3% | 0.5/ 7.5fps |
| LBP-Channels selected | 13.6% | 0.7/ 10fps |
| FRCNN [110] | 13% | 7fps |
| RPN+PF [140] | 7% | 6fps |
| Evaluation method | Log-average miss rate | Speed(CPU/GPU) |
| HoG [59] | 69% | 0.5fps |
| DPM [70] | 63.26% | 1fps |
| FeatSynth [45] | 60.16% | 1fps |
| MultiFeatures+CSS [123] | 60.89% | No |
| FPDW [64] | 57.4% | 2-5fps |
| Channel Features [64] | 56.34% | 0.5fps |
| Roerei [46] | 48.35% | 1 fps |
| MOCO [54] | 45.5% | 1fps |
| JointDeep [103] | 39.32% | 1fps |
| SquaresChnFtrs [47] | 34.8% | 1fps |
| InformedHaar [137] | 34.6% | 0.63fps |
| Spatial pooling [104] | 29.2% | 1fps |
| Checkboards [138] | 24.4% | 1fps |
| FRCNN [110] | 56% | 7fps |
| CrossTalk cascades [66] | 53.88% | 30-60fps |
| WordChannels [57] | 42.3% | 0.5/8fps |
| LBP-Channels full | 39.1% | 0.5/ 7.5fps |
| LBP-Channels selected | 35.9% | 0.7/ 10fps |
| SSD [92] | 34% | 56fps |
| RPN+PF [140] | 10% | 6fps |